Building a Crypto Price Predictor with GCP - Part 2 - Fetching Crypto Data on a Daily Basis

Today, we are making it rain.

That's right, you heard me.
We are gonna become greedy-little-data-hoarders.
Today's blog post focuses on the data retrieval part of the plan we forged together in the first post of the series:
 Javier Cabrera
Javier Cabrera
Just in case you haven't read it yet.
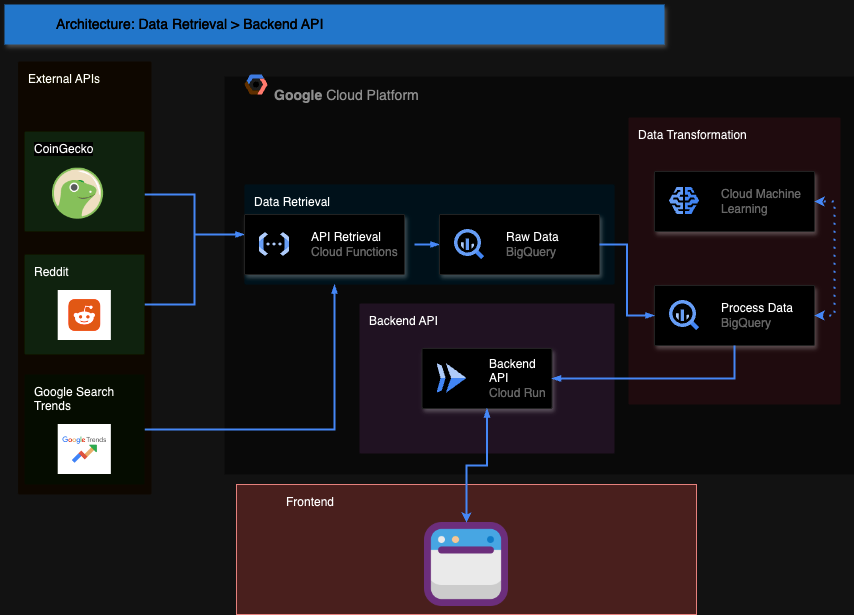
The plan for today is to build a prototype data pipeline, where we will retrieve daily data from:
- CoinGecko: To fetch crypto-currency prices.
- Bitcoin, Ethereum, Chainlink, Solana, SUI
- Reddit: Data from cryptocurrency and financial subreddits.
- Google Trends: Volume of searches of keywords related to our coins.
We will leverage Python, APIs, and Google Cloud to automate daily retrieval.
Today's tutorial will focus on the process of fetching crypto data. The techniques and ways of thinking through the problem apply to the rest of the APIs we will use in our MVP.
I'm unsure if I will add posts for the remaining APIs. If I don't, this post can serve as an example of the process.
With the intro out of the way, let's get to it.
Fetching Data with the CoinGecko API
The first step in building the pipeline was creating the code to let me interact with CoinGecko's API.
Why did I pick this particular API?
In short, I used it because it had the data I was looking for and a free tier I could query. However, working with it, I found it has excellent documentation, which is also a plus.
Selecting the Crypto Currencies
With that out of the way, I had to make a decision. Mainly, what coins did I want to retrieve?
I had to select coins I'd potentially like to predict with my model and anything that might serve as a sound input feature.
I want to tell you that I did a deep analysis to make my selection, but I did not. I went with a combination of coins I remembered from when I followed the crypto space and two suggestions from my boss.
The selected coins were:
- Bitcoin: The Michael Jordan of crypto-currencies. Even your grandma probably owns some. I probably won't be trying to predict its price, but I am sure it could be a relevant input into my model.
- Ethereum: My first love in the crypto space. To me, the promise of crypto was not in its money-making potential but in its promise of a decentralized world. To me, ethereum would be the Microsoft of this promised new world. It may also serve as an excellent input feature to our model.
- ChainLink: The oracle of DEFI. It's another pick born out of love and nostalgia—a potential target for our predictor variable.
- SUI: To be honest, all I know about SUI is that it is built by ex-Meta employees. There is some hype to it, and the low price would make it an easy pick for me to act on the output of the model we will be building.
Data Retrieval Phases
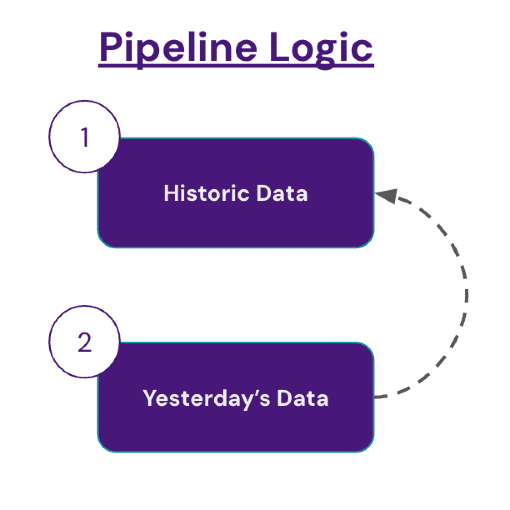
The idea is to retrieve the data in two main phases.
- Phase 1: Historical Data Retrieval
- Right now, there are still some questions.
- For example, we don't know how much data we will use for our model. Will we train our model on ten years of data? On one?
- Our coins also have different creation dates. For example, SUI was created around May of last year.
- With this in mind, we won't be fetching too much. We'll probably only fetch about four years' worth of data for the coins we can, and for SUI, approximately two years' worth of data will be available.
- Phase 2: Daily Retrieval of Yesterday's Data
- Once the historical retrieval is ready, we will create a process to update our tables with yesterday's data. We want our predictor to be helpful for short-term trading, so we should probably make predictions daily at the very least.
Step 1: Extracting Historic Crypto Data
As a disclaimer, although I program in Python, I won't claim to be an expert programmer. I know enough to get around but do not expect heavily optimized code.
Although we plan to deploy this code in Google Cloud, we will do the historic retrieval locally and manually upload the dataset to GCP.
Before going through the code, let's discuss the database structure.
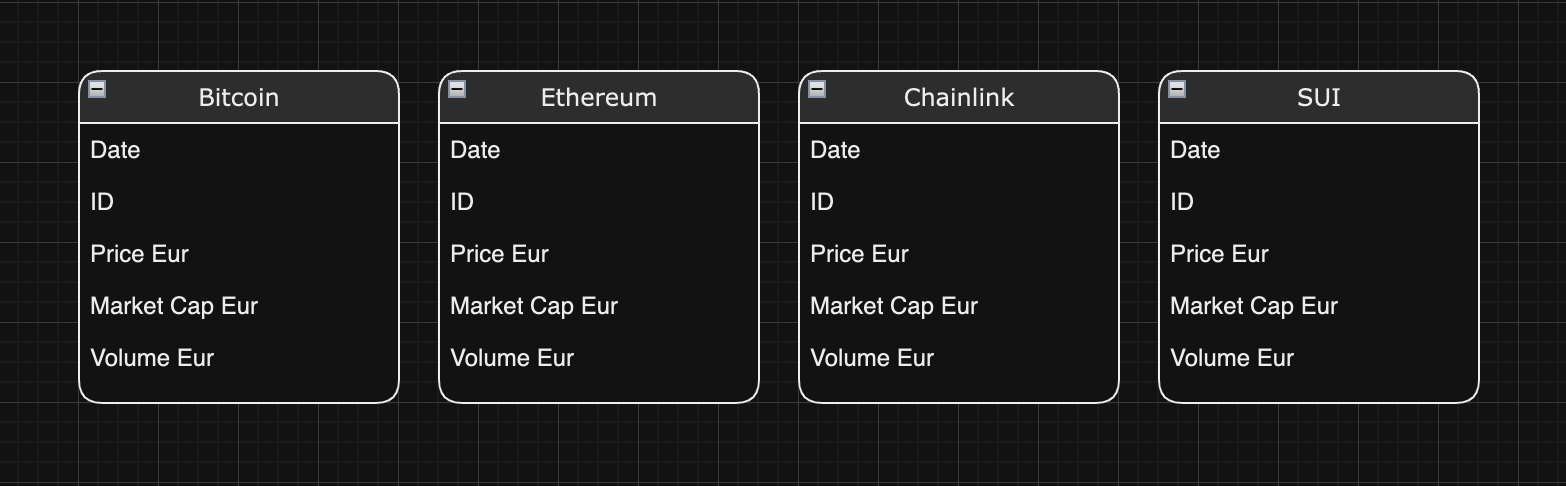
Our architecture here is a simple one. Each table represents a cryptocurrency, and they all contain the same columns:
- Date
- ID
- Price Eur
- Market Cap
- Volume Eur
Querying the Coin List Endpoint
We will use the Coin Historical Chart Data by ID endpoint. The endpoint accepts the following parameters:
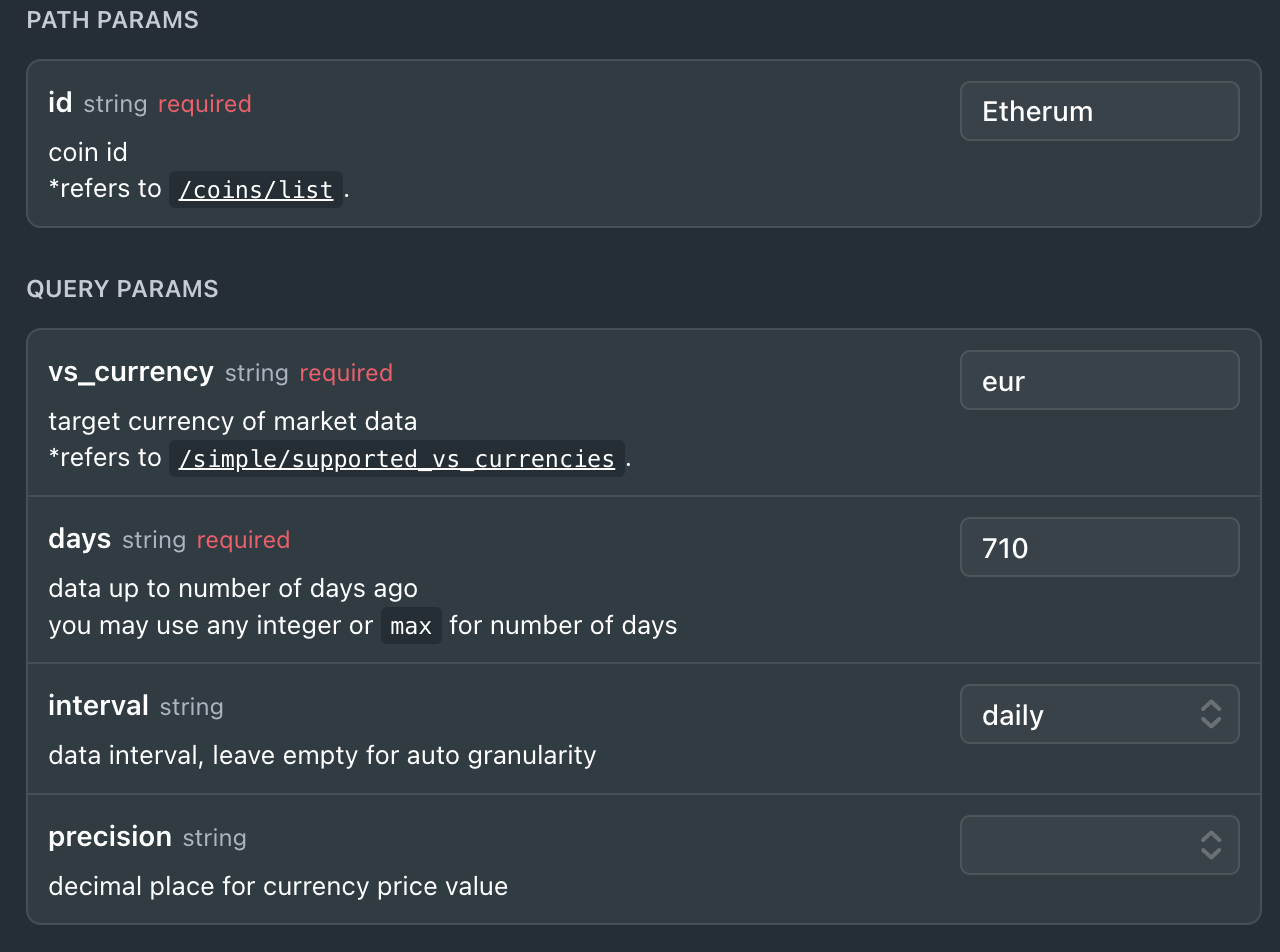
You might have noticed that the Path Params section lists it as a required field. This relates to a particular ID representing each coin in CoinGecko's back-end. To figure out the IDs for our coins, we must first query the Coins List endpoint.
We do this with the following snippet of code:
import requests
import pandas as pd
from datetime import datetimeWe will be leveraging these three libraries for our data retrieval.
def getcoinslist():
# Get Crypto Coins List
url = 'https://api.coingecko.com/api/v3/coins/list'
# Make the GET request
response = requests.get(url)
# Checking the status code
if response.status_code == 200:
print('Success')
else:
print(f"Error: {response.status_code} - {response.reason}")
#turn the response to a dataframe
crypto_coins = response.json()
crypto_coins = pd.DataFrame(crypto_coins) # Let's make it a DataFrame
return crypto_coins
#We use the function to get a list of cryptocurrencies
coins = getcoinslist()Simple python function to query coins list api.
We use this code to come up with a list of cryptocurrencies:
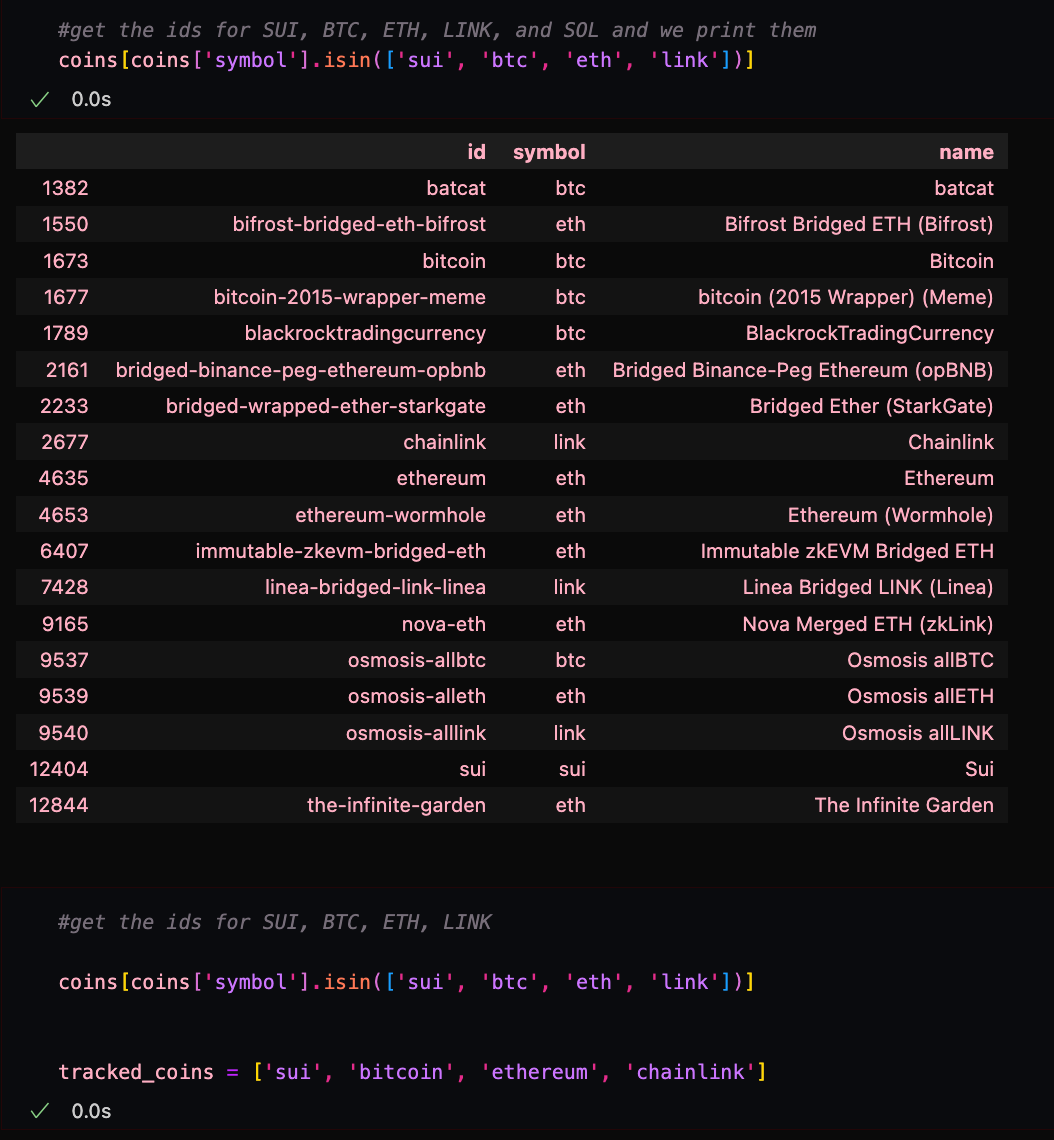
As you can see, this is important, as there are a lot of "knock-off" coins with the same symbols but none with identical IDs.
Querying the Historical Data Endpoints
Armed with our coin list, we build another function that extracts historical data for each coin and outputs a table with all of them.
We do this by creating two main functions, one for fetching data and another for processing it.
The code looks like this:
# Configure logging
logging.basicConfig(level=logging.INFO)
def fetch_market_chart_data(coin_id, vs_currency, days, interval):
url = f"https://api.coingecko.com/api/v3/coins/{coin_id}/market_chart"
params = {
'vs_currency': vs_currency,
'days': days,
'interval': interval
}
try:
response = requests.get(url, params=params)
response.raise_for_status()
data = response.json()
return data
except requests.exceptions.HTTPError as http_err:
logging.error(f"HTTP error occurred for {coin_id}: {http_err}")
except Exception as err:
logging.error(f"An error occurred for {coin_id}: {err}")
return None
def process_market_chart_data(data, coin_id):
if data is None:
logging.warning(f"No data available for {coin_id}")
return None
# Convert lists to DataFrames
prices_df = pd.DataFrame(data['prices'], columns=['timestamp', 'price'])
market_caps_df = pd.DataFrame(data['market_caps'], columns=['timestamp', 'market_cap'])
volumes_df = pd.DataFrame(data['total_volumes'], columns=['timestamp', 'volume'])
# Merge DataFrames on timestamp
df = prices_df.merge(market_caps_df, on='timestamp').merge(volumes_df, on='timestamp')
# Convert timestamp from milliseconds to datetime
df['date'] = pd.to_datetime(df['timestamp'], unit='ms').dt.date
# Add coin ID
df['coin_id'] = coin_id
# Reorder columns
df = df[['date', 'coin_id', 'price', 'market_cap', 'volume']]
return df
# List of coins
tracked_coins = ['sui', 'bitcoin', 'ethereum', 'chainlink']
# Target currency
vs_currency = 'eur'
# Number of days
days = 354
# Data interval
interval = 'daily' # Options are 'daily' or 'hourly'
# Dictionary to store DataFrames per coin
coin_dataframes = {}
for coin_id in tracked_coins:
logging.info(f"Fetching data for {coin_id}")
data = fetch_market_chart_data(coin_id, vs_currency, days, interval)
df = process_market_chart_data(data, coin_id)
if df is not None:
coin_dataframes[coin_id] = df
time.sleep(3) # Sleep to respect API rate limits
else:
logging.warning(f"No data retrieved for {coin_id}")
# Display the data
for coin_id, df in coin_dataframes.items():
print(f"\nData for {coin_id}:")
display(df.head(2))
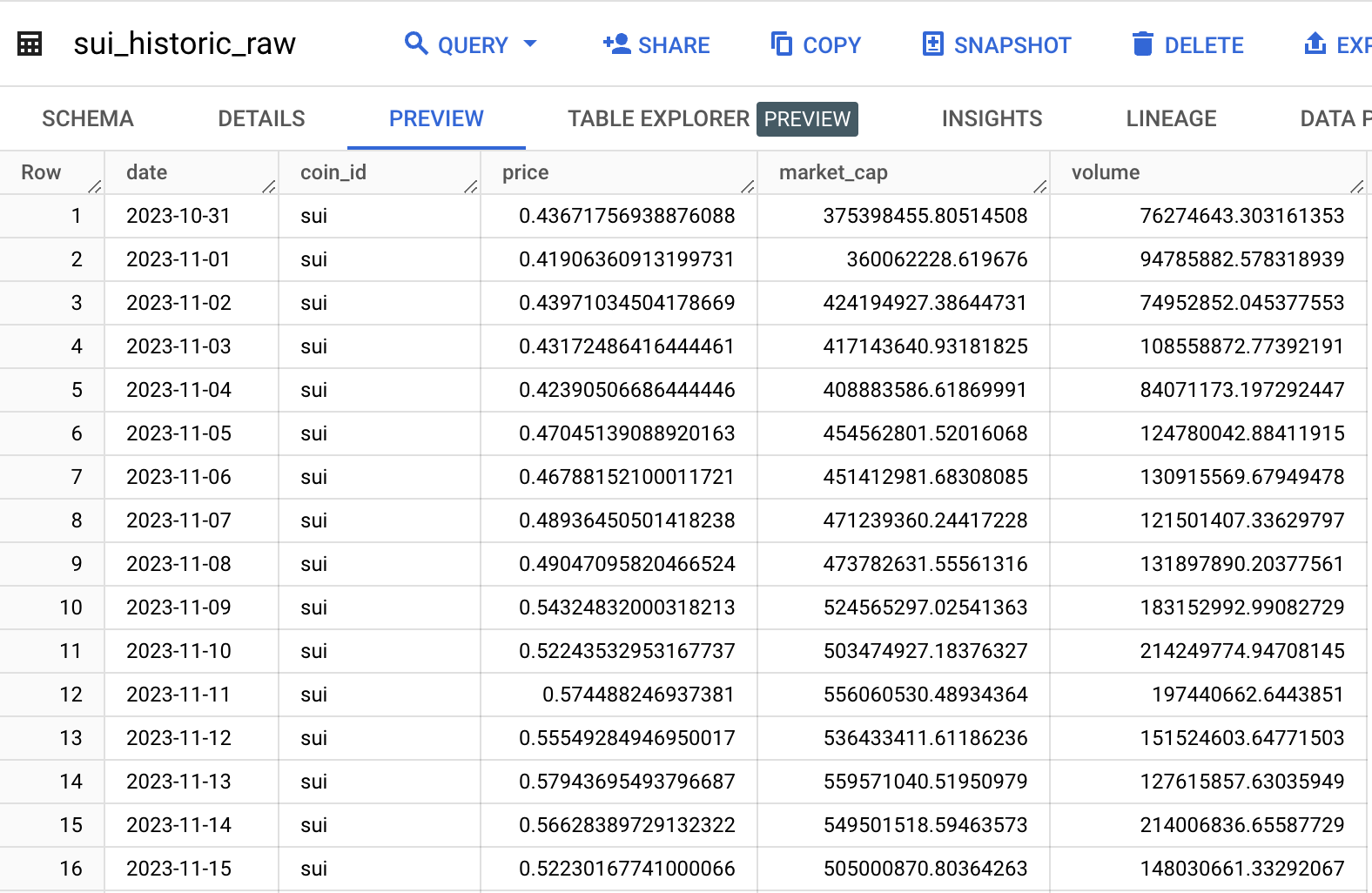
We store and download the data to CSVs and manually upload it to BigQuery.
Step 2: Restructure Code to Append Daily Data Using a Cloud Function
We want to automate the retrieval process because we do not want to update the data manually.
For this, we will use a Cloud Function, a GCP service that allows you to execute code when an event happens, in our case, at a specific time each day.
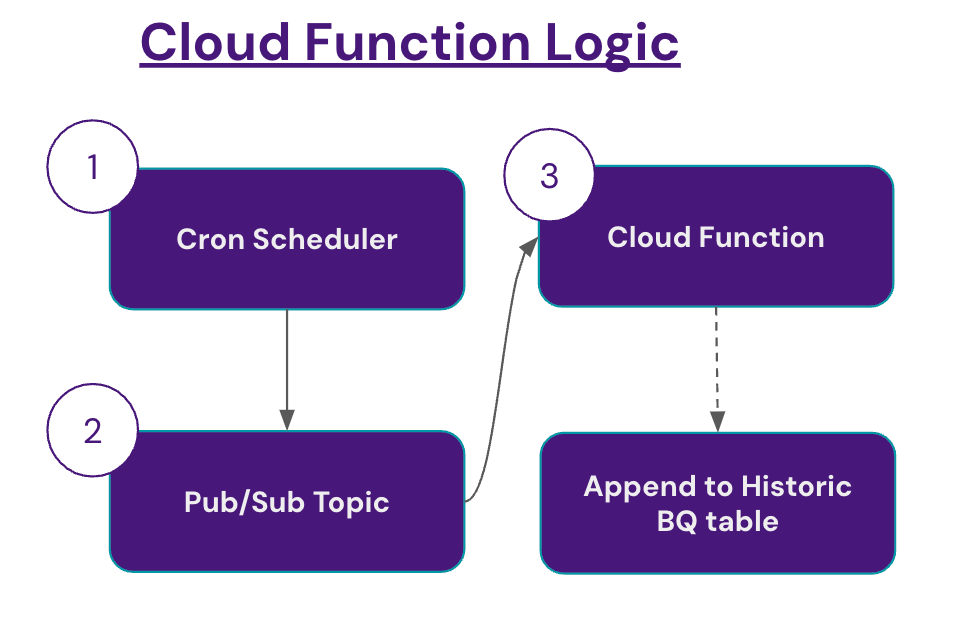
The basic work-flow of our solution is the following:
- Cron-Scheduler: We set up a CRON job so that everyday, at 7:00 am madrid time, a pub-sub topic fires.
- Pub/Sub Topic: A cloud messaging service that we can use to execute our cloud function.
- Cloud Function: Our python code that retrieves data and appends it to BigQuery.
Today, I won't be guiding you through the whole process of setting this up. If you want me to dedicate a specific blog post about this, don't hesitate to leave me a comment.
As for the code we run in our cloud function, its a slight variation of the code previously posted, where we set days to 2 instead of the full year period, and we add a couple of extra python functions to process the data and append it directly to BigQuery.
This is the code I deployed. Before deploying it yourself, make sure to scan the code and change variables so that they adapt to your set up and naming convention.
import requests
import pandas as pd
import time
import logging
from datetime import datetime, timedelta
import os
from google.cloud import bigquery
from google.cloud.exceptions import NotFound
# Configure logging
logging.basicConfig(level=logging.INFO)
def fetch_market_chart_data(coin_id, vs_currency, days, interval):
url = f"https://api.coingecko.com/api/v3/coins/{coin_id}/market_chart"
params = {
'vs_currency': vs_currency,
'days': days,
'interval': interval
}
try:
response = requests.get(url, params=params)
response.raise_for_status()
data = response.json()
return data
except requests.exceptions.HTTPError as http_err:
logging.error(f"HTTP error occurred for {coin_id}: {http_err}")
except Exception as err:
logging.error(f"An error occurred for {coin_id}: {err}")
return None
def process_market_chart_data_for_yesterday(data, coin_id):
if data is None:
logging.warning(f"No data available for {coin_id}")
return None
# Convert lists to DataFrames
prices_df = pd.DataFrame(data['prices'], columns=['timestamp', 'price'])
market_caps_df = pd.DataFrame(data['market_caps'], columns=['timestamp', 'market_cap'])
volumes_df = pd.DataFrame(data['total_volumes'], columns=['timestamp', 'volume'])
# Merge DataFrames on timestamp
df = prices_df.merge(market_caps_df, on='timestamp').merge(volumes_df, on='timestamp')
# Convert timestamp from milliseconds to datetime
df['date'] = pd.to_datetime(df['timestamp'], unit='ms').dt.date
# Calculate yesterday's date
yesterday = datetime.utcnow().date() - timedelta(days=1)
# Filter data for yesterday
df = df[df['date'] == yesterday]
if df.empty:
logging.warning(f"No data available for {coin_id} on {yesterday}")
return None
# Since we have daily data, there should be only one row
df = df.iloc[0:1]
# Add coin ID
df['coin_id'] = coin_id
# Reorder columns
df = df[['date', 'coin_id', 'price', 'market_cap', 'volume']]
return df
def upload_to_bigquery_append(df, dataset_id, table_id):
client = bigquery.Client()
table_ref = client.dataset(dataset_id).table(table_id)
job_config = bigquery.LoadJobConfig(
write_disposition=bigquery.WriteDisposition.WRITE_APPEND
)
# If the table does not exist, create it with partitioning
try:
client.get_table(table_ref)
except NotFound:
create_table_with_partitioning(client, dataset_id, table_id)
job = client.load_table_from_dataframe(df, table_ref, job_config=job_config)
job.result() # Wait for the job to complete
logging.info(f"Appended {len(df)} rows to {dataset_id}.{table_id}")
def create_table_with_partitioning(client, dataset_id, table_id):
table_ref = client.dataset(dataset_id).table(table_id)
schema = [
bigquery.SchemaField('date', 'DATE'),
bigquery.SchemaField('coin_id', 'STRING'),
bigquery.SchemaField('price', 'FLOAT'),
bigquery.SchemaField('market_cap', 'FLOAT'),
bigquery.SchemaField('volume', 'FLOAT'),
]
table = bigquery.Table(table_ref, schema=schema)
table.time_partitioning = bigquery.TimePartitioning(
type_=bigquery.TimePartitioningType.DAY,
field='date',
)
client.create_table(table)
logging.info(f"Created partitioned table {dataset_id}.{table_id}")
def record_exists(client, dataset_id, table_id, date, coin_id):
query = f"""
SELECT COUNT(1) as count
FROM `{client.project}.{dataset_id}.{table_id}`
WHERE date = @date AND coin_id = @coin_id
"""
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter('date', 'DATE', date),
bigquery.ScalarQueryParameter('coin_id', 'STRING', coin_id),
]
)
query_job = client.query(query, job_config=job_config)
result = query_job.result()
count = next(result).count
return count > 0
def main(event=None, context=None):
logging.info("Cloud Function has been triggered.")
# Environment variables
DATASET_ID = os.environ.get('DATASET_ID', 'crypto_data_raw')
VS_CURRENCY = os.environ.get('VS_CURRENCY', 'eur')
TRACKED_COINS = os.environ.get('TRACKED_COINS', 'sui,bitcoin,ethereum,chainlink').split(',')
# Data interval and days
days = 2 # Fetch data for the last 2 days to get yesterday's data
interval = 'daily'
# Dictionary to store DataFrames per coin
coin_dataframes = {}
for coin_id in TRACKED_COINS:
logging.info(f"Fetching data for {coin_id}")
data = fetch_market_chart_data(coin_id, VS_CURRENCY, days, interval)
df = process_market_chart_data_for_yesterday(data, coin_id)
if df is not None:
coin_dataframes[coin_id] = df
time.sleep(1) # Sleep to respect API rate limits
else:
logging.warning(f"No data retrieved for {coin_id} for yesterday")
# Upload data to BigQuery
client = bigquery.Client()
for coin_id, df in coin_dataframes.items():
table_id = f'{coin_id}_historic_raw'
# Get yesterday's date
yesterday = datetime.utcnow().date() - timedelta(days=1)
# Check if record exists
if record_exists(client, DATASET_ID, table_id, yesterday, coin_id):
logging.info(f"Data for {coin_id} on {yesterday} already exists in {DATASET_ID}.{table_id}")
continue # Skip uploading
# Append data
upload_to_bigquery_append(df, DATASET_ID, table_id)
Code adapted for our cloud function and for daily retrieval.
Conclusion
Well, fellow data hoarders, that's a wrap for today.

We've rolled up our sleeves and built ourselves a pipeline to fetch and store crypto prices for Bitcoin, Ethereum, Chainlink, and SUI.
We ventured into the realm of CoinGecko's API, wrote some Python magic, and even got a Cloud Function buzzing to keep our data flowing daily into BigQuery.
We've laid down a solid foundation and a framework that'll make wrangling data from our other sources a breeze. If you're itching for more on setting up the cloud bits, don't be shy—drop a comment and let me know.
We've taken a big step towards our ultimate goal: building that crypto price predictor. Next up, we'll dive into fetching data from Reddit and Google Trends because, let's face it, there's no such thing as too much data when you're on a mission like ours.
Stay tuned, keep hoarding, and as always, happy data hunting!
Member discussion