Take Your First Steps in Marketing Mix Modeling Using Google's Meridian Python Library

Imagine you are your company's CMO and tasked with driving your company's growth.
You have a yearly budget and must decide how to spend it.
What do you do?
Enter Marketing Mix Modeling (MMM), one of 2025's hottest marketing terms.
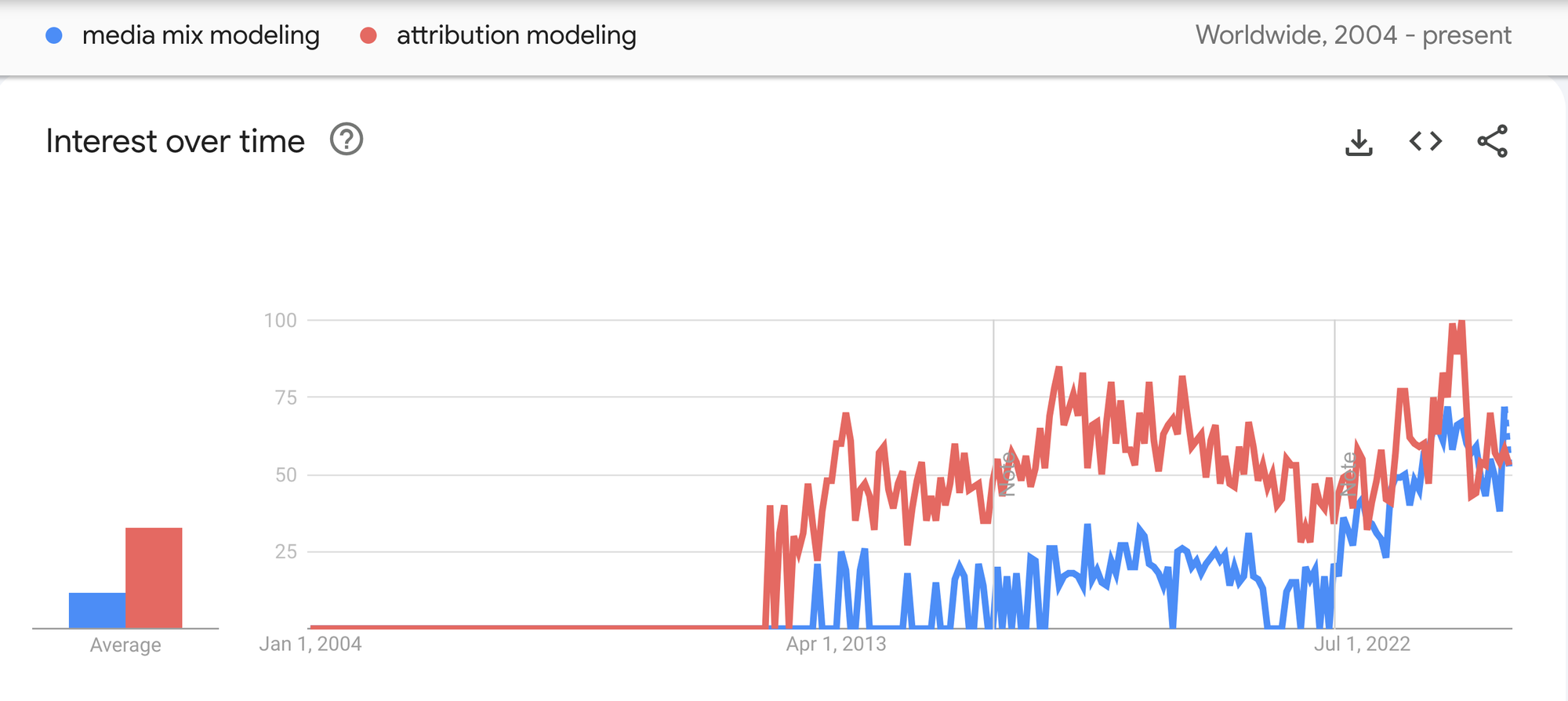
The growing interest comes from the rising impact of privacy features in tech. For example, some browsers have already diminished tracker duration to just one day. These factors render traditional channel attribution models less effective.

Check out this article to learn about classic attribution models and how privacy shifts have impacted them.
This article is here to help you understand MMMs by walking through a demo deployment.
Together, we’ll explore MMM using synthetic data and follow through the DEMO of Google's Meridian Python Library
So, What is Media Mix Modelling?
Marketing Mix Modeling (MMM) examines historical performance data to understand how marketing channels influence outcomes. These models facilitate the analysis of previous results and the creation of optimization scenarios drawn from that analysis.
In contrast to attribution modeling, MMM utilizes a broad perspective that is unaffected by signal loss due to privacy changes.
Understanding How the Use of Aggregate Data Makes MMM Privacy Resistant
A key distinction between MMMs and traditional attribution models is the type of data they rely on.
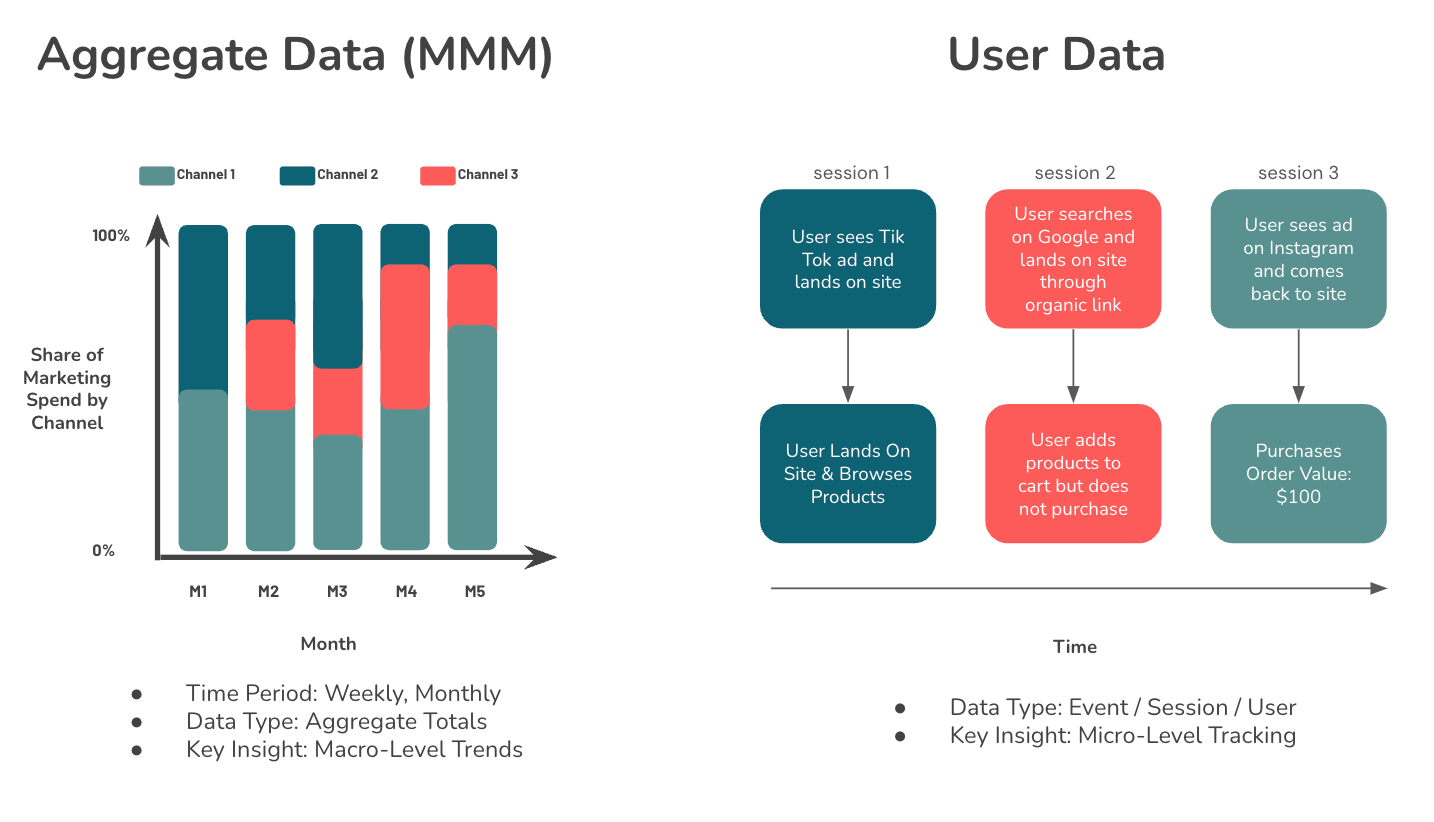
Attribution models distribute credit for conversions across the user's previous digital touchpoints. To properly distribute revenue to the relevant marketing channels, you must first know the marketing channels that impacted the conversion.
This has become increasingly difficult. The deprecation of 3rd party cookies, current limits on cookie lifetime in browsers such as Safari and Firefox, and the rise of ad-blockers have made having a complete picture of users' purchase journeys almost impossible.
Attribution models, by their nature, depend on users performing a trackable action after interacting with an ad. Typically, this requires users to directly visit your site by clicking the ad. This reliance on direct actions often downplays the effectiveness of top-of-funnel or branding strategies that may not prompt immediate user interaction.
Another problem with the micro view provided by attribution models is that they tend to overstate the influence of marketing. They do not account for seasonality or baseline demand for a product; to them, any transaction that came through a marketing channel is attributable when, in fact, the user might have bought the product regardless of your marketing efforts.
MMMs offer a different perspective that can help mitigate the problems with attribution modeling stated above.
Running MMM with Meridian
Many open-source tools can assist marketers in their marketing mix modeling. Following Meta's lead with Robyn, Google released Meridian, their vision of an open-source MMM solution.
Today, we will run through the demo for Meridian while explaining some of the concepts needed to understand how the model works and how to use it to power up your marketing decisions.
1) Preparing and Understanding the Input Data
The first step in any MMM project is collecting and preparing your data. The Meridian Model requires the following data:
- Time: The time granularity of the data. Best practice is to provide the model with weekly data, but monthly may work too.
- GEO: Data should also be segmented on location basis.
- KPI: The Y variable or the target KPI for the model to predict. For example, revenue amount or number of application installations.
- Media Spend: Containing the media spend per channel and period.
- Media Data: Exposure metric per channel and time. It cannot contain negative values. If no metrics are available, use the same as in media spend.
- Control variables: Confounder variables that might have a causal effect on the target KPI and the media metrics (spend, impressions, etc). For example, Google Search Queries related to your product or macroeconomic factors might be suitable confounder variables. The selection of control variables is essential for estimating the causal effect.
- Geo population: Contains the population for each geo. Geo population (such as Nielsen DMA TV household population) is used to scale the media metric to put all Geolocation data on a comparable scale.
Generating Synthetic MMM Data
Google's demo comes with some pre-made synthetic data. However, we wanted to do something more creative, so we generated our own.
The synthetic data includes:
- 4 GEOS (ES, UK, FR, DE)
- 4 Channels (Facebook Branded, Facebook Conversion, YouTube Branded, Google Search Branded, and Google Search Non-Branded
- 3 years' worth of weekly data.
We simulated the MMM data by building some "ground truths" into it. We did this by making assumptions about the distribution of the impact of the marketing channels on revenue. However, to not make it easy for the model, we introduced a lot of random noise and variability into our data.
What we should expect to see:
- No Extremely Dominant Channel, But GADS Non-Branded is slight winner: We used coefficients to model the data so that no overly dominant channel would be found. We should probably expect "Google Ads Non-Branded" to have a slightly higher ROI and effectiveness due to a higher upper bound in the random distribution.
- A High Baseline Revenue: Baseline revenue should be pretty high (Higher than 70% of revenue) due to the substantial impacts of seasonality and other confounding variables we hardcoded into the model.
With the data synthesized, it's time to run the model.
2) Mapping our data to Meridians Fields
Meridian needs data to be passed in a specific format to run correctly. To do so, we build a set of objects with key-value mapping to our datasets columns:
##We map our DF columns to the corresponding variables needed by Meridian
coord_to_columns = load.CoordToColumns(
time='Date', #week
geo='Geo',
controls=['Google_Query_Volume', 'Economic_Factor'],
population='Geo_Population',
kpi='Revenue',
revenue_per_kpi='revenue_per_conversion',
##the media exposure metric (Modeled Impressions)
media=[
'facebook_brand_exposure',
'facebook_conversion_exposure',
'youtube_brand_exposure',
'google_search_branded_exposure',
'google_search_non_branded_exposure',
],
media_spend=[
'facebook_brand',
'facebook_conversion',
'youtube_brand',
'google_search_branded',
'google_search_non_branded',
],
#reach =['Channel4_reach', 'Channel5_reach'],
#frequency=['Channel4_frequency', 'Channel5_frequency'],
#rf_spend=['Channel4_spend', 'Channel5_spend'],
#non_media_treatments=['Discount'],
)
correct_media_to_channel = {
'facebook_brand_exposure': 'facebook_brand',
'facebook_conversion_exposure': 'facebook_conversion',
'youtube_brand_exposure': 'youtube_brand',
'google_search_branded_exposure': 'google_search_branded',
'google_search_non_branded_exposure': 'google_search_non_branded',
}
correct_media_spend_to_channel = {
'facebook_brand': 'facebook_brand',
'facebook_conversion': 'facebook_conversion',
'youtube_brand': 'youtube_brand',
'google_search_branded': 'google_search_branded',
'google_search_non_branded': 'google_search_non_branded',
}
Excerpt from our code
We then create a data object to feed into Meridian using the DataFrameLoader module.
#dataframe data loader
loader = load.DataFrameDataLoader(
df=df,
coord_to_columns= coord_to_columns,
kpi_type= 'revenue',
media_to_channel= correct_media_to_channel,
media_spend_to_channel= correct_media_spend_to_channel,
)
data=loader.load()3) Setting Up and Running the Models
With the data mapped, it's time to set up our model. The first step is to set our models specifications.
Meridian starts with the following default configuration:
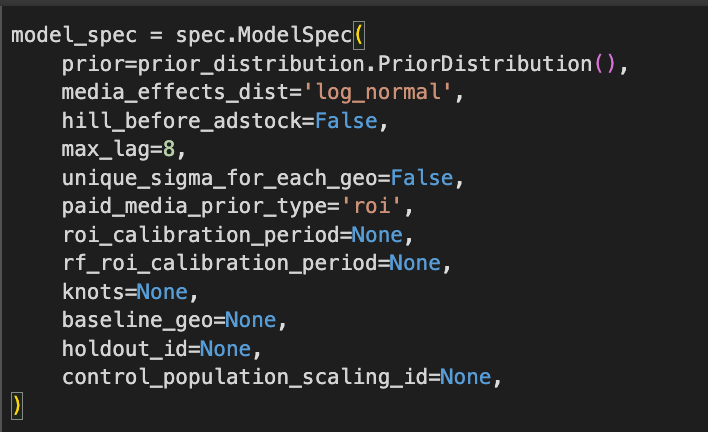
It takes the following values:
- Prior: Priors are a way to impact the model's assumptions. They are used to pass domain knowledge to the model, making it more robust and align better with the real world.
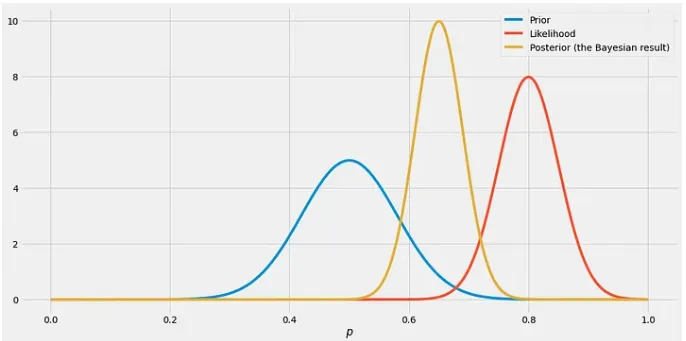
- Priors can be either a constant across channels or passed on a per-channel basis.
- See the example below where each channel has an assigned ROI prior:

- More information about Meridian's priors can be found at the link.
- media_effects_dist: Specifies how media effectiveness is distributed across geos (log_normal vs normal)
- hill_before_adstock: Determines whether the Hill function (non-linear response to spend) is applied before Adstock (carryover effect).
- max_lag: Sets the maximum carryover duration (in weeks) for media impact. Defaults to 8.
- paid_media_prior_type: Determines whether ROI or direct coefficients are used to model paid media effectiveness.
- roi_calibration_period: Allows defining a time window to calibrate ROI values.
And others...
You can read more about all of Meridians Model Specs here.
For this guide, we ran two models. One of them included priors and another one didn't. The first model assumed an ROI prior across all channels. The second ran without any previous knowledge.
If you are following along with the collab, please note that running the model can take some time (around 7-10 mins per run).
4) Evaluating the Models
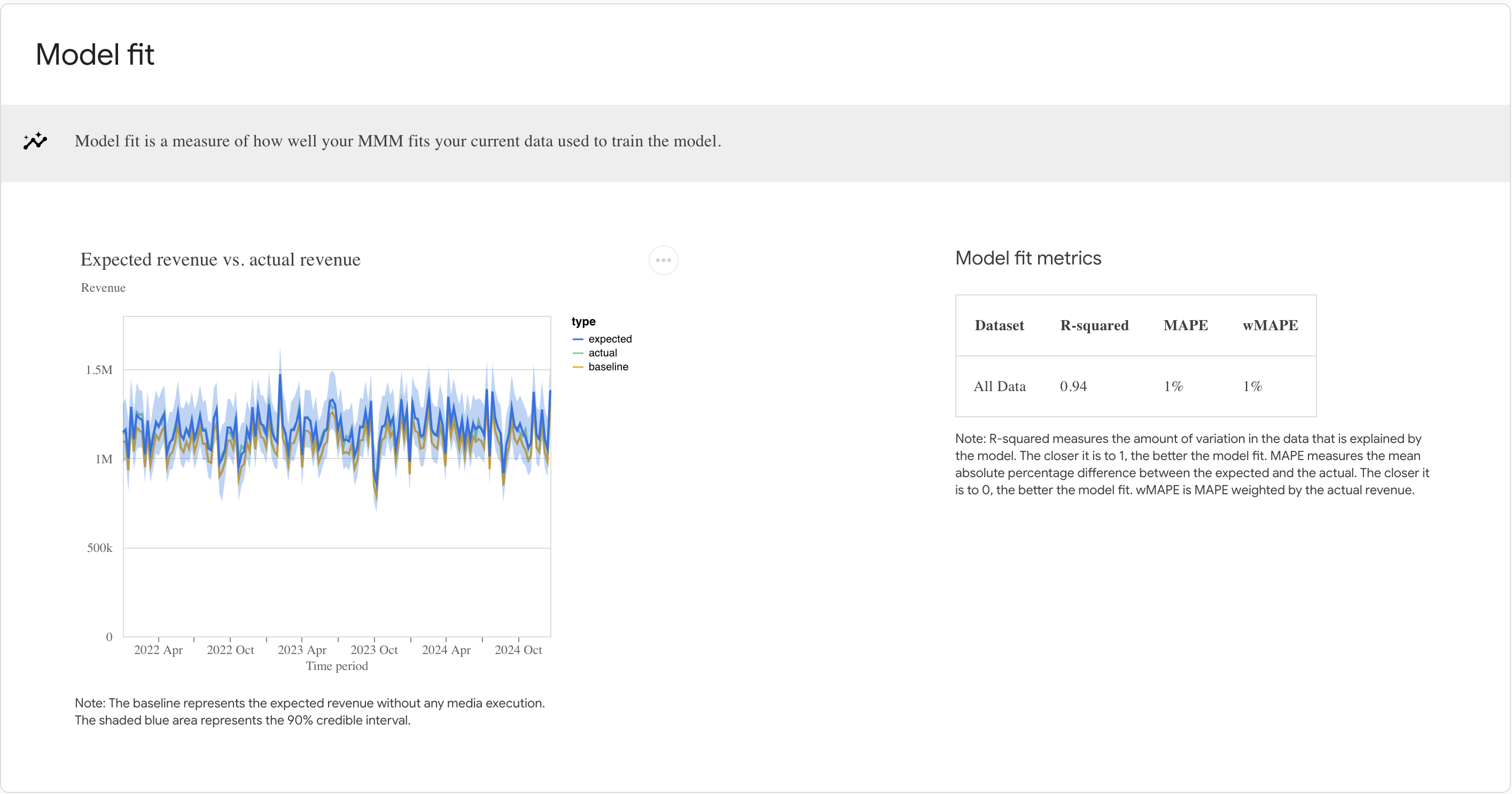
One of the ways we can evaluate our model is by checking if the model's Revenue prediction (the blue line) is close to the actual value (green line). This can be done very simply with three lines of code in meridian:
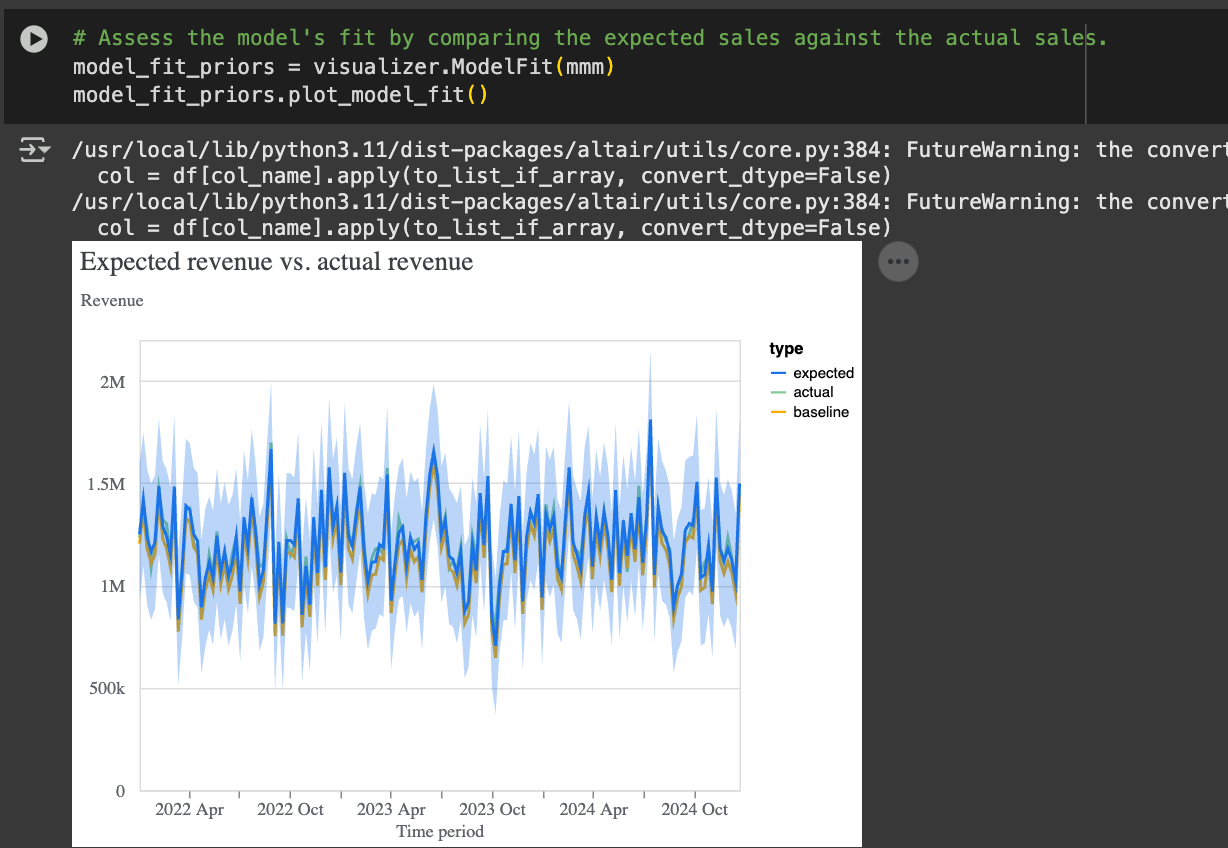
Model fit can also be assessed by looking at Metrics such as the R-squared once you call the model summarizer method:

An R-squared higher than .9 means the model is pretty good at explaining the variance in revenue.
5) Getting our MMM Summary Analysis
The cool thing about Meridian is that it creates an automated report with a couple of lines of code:
mmm_summarizer = summarizer.Summarizer(mmm)
from google.colab import drive
drive.mount('/content/drive')
filepath = '/content/drive/MyDrive'
start_date = "2022-01-02"
end_date = "2024-12-22"
mmm_summarizer.output_model_results_summary('summary_output.html', filepath, start_date, end_date)This command spits out an HTML document with an analysis of the effect of our marketing channels. If you want to check out the one we got for our synthetic data, download and open the file below:
The summary consists of the following:
- Analysis of Model Fit: The model fit analysis indicates how well the predicted revenue aligns with actual data.
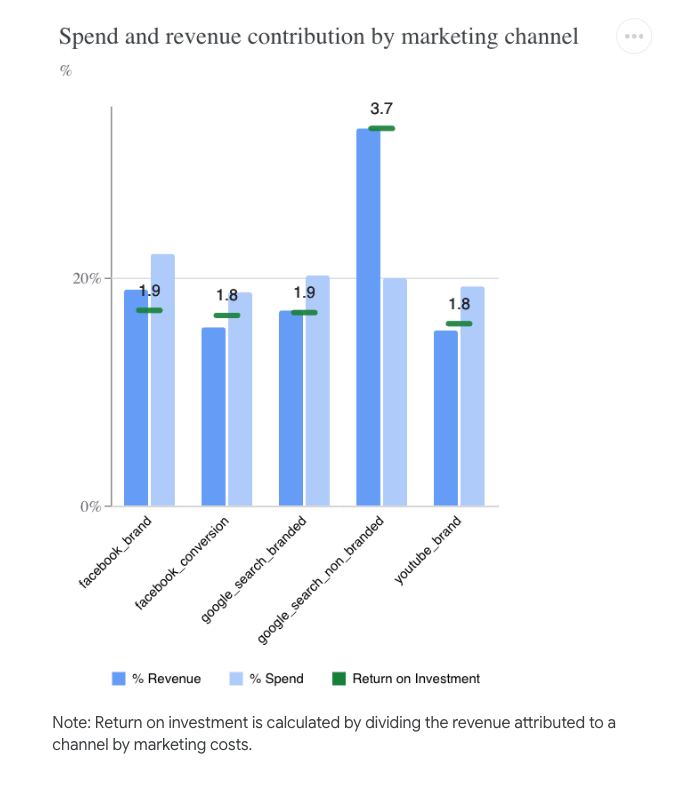
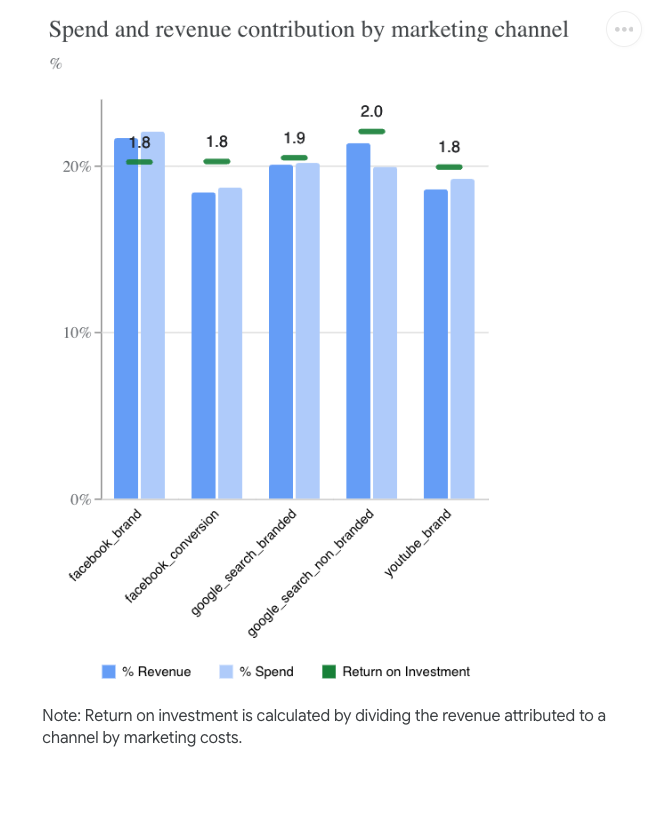
- Channel Contribution: Analysis of the impact of our marketing channels on our KPI.
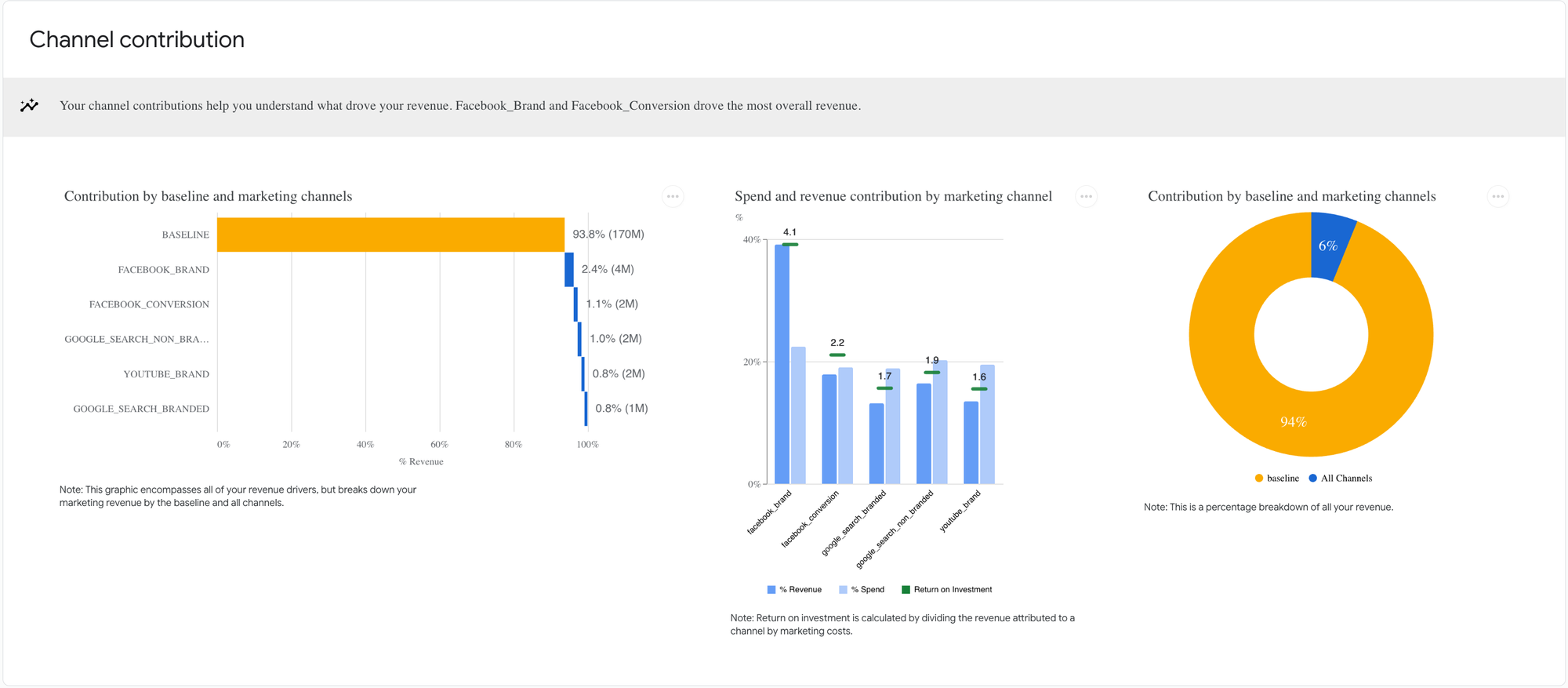
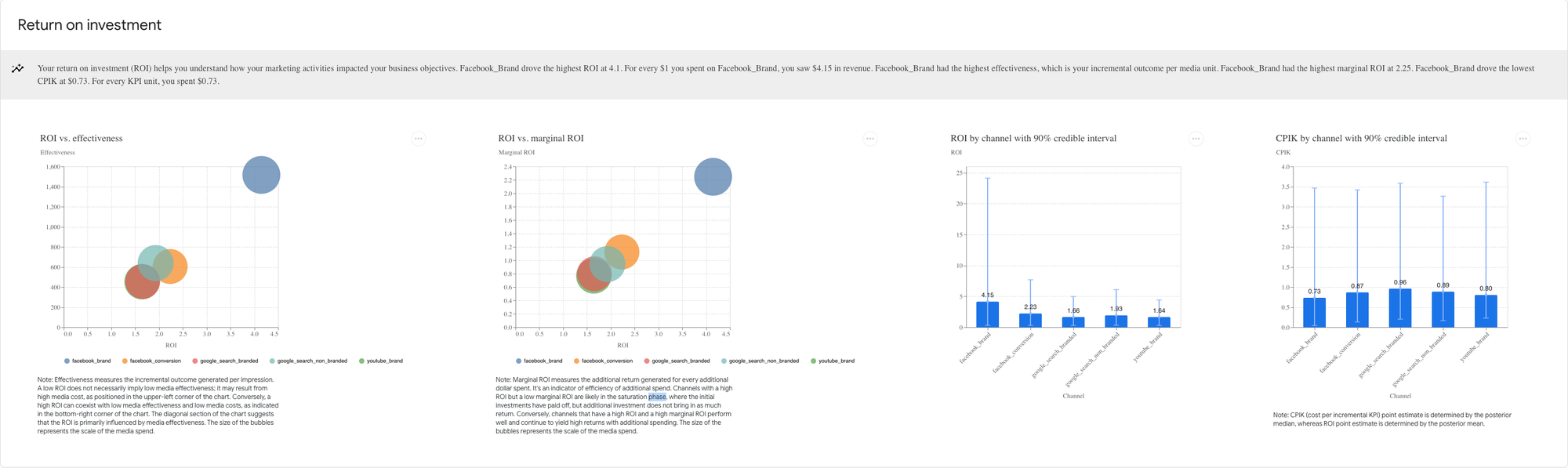
In our synthetic dataset, Marketing spending only accounts for 6% of revenue, and Facebook_Brand has the highest ROI, generating 4$ per 1$ invested.
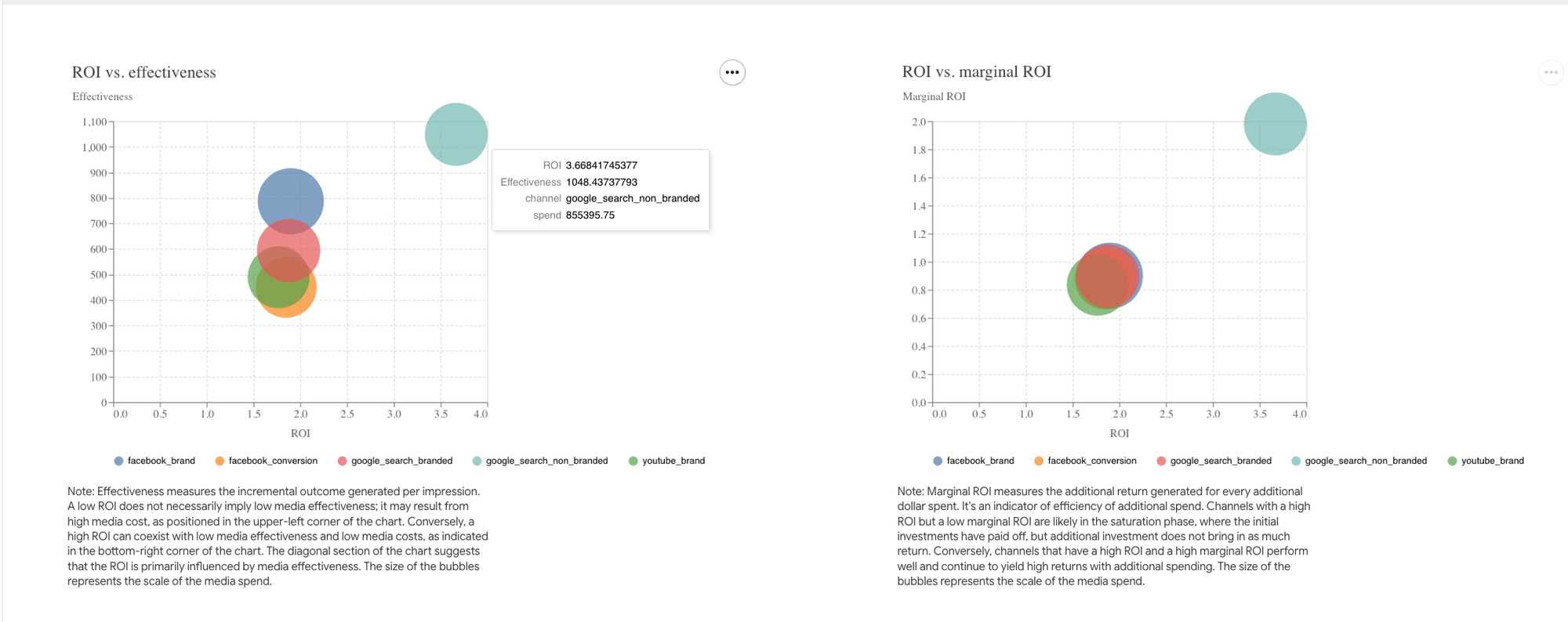
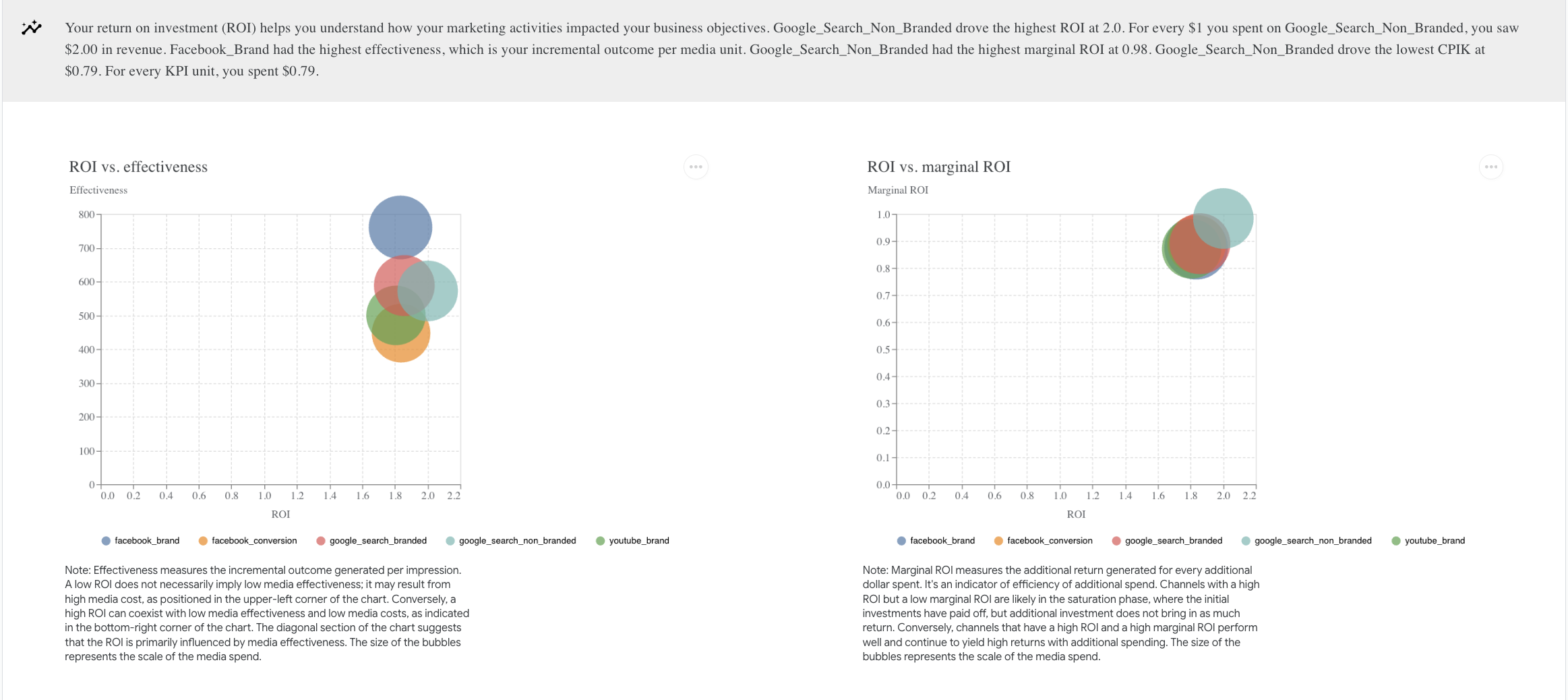
- Return on Investment: This section is dedicated to understanding our marketing channels' ROI, effectiveness, and marginal ROI.
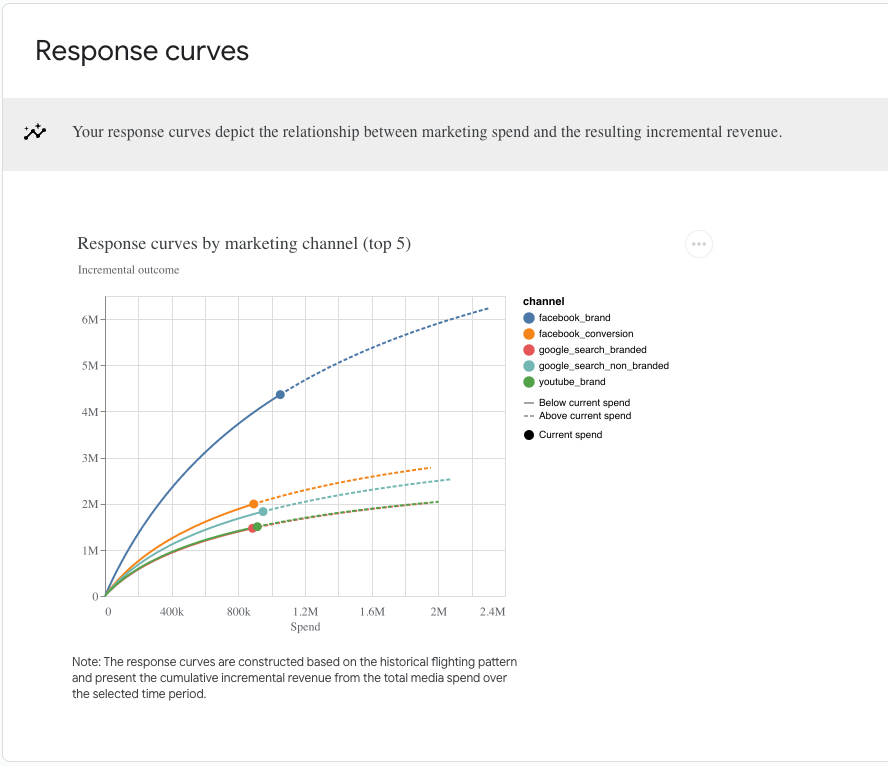
- Response Curves: Depict the model's estimation of the relationship between marketing spend and incremental revenue:
6) Getting our Budget Optimization Report
As with the model results, there is a quick and easy report we can run with just a few lines of code.
You can adapt some of the parameters of the budget optimization scenario by playing around with the budgetOptimizer.Optimize class:
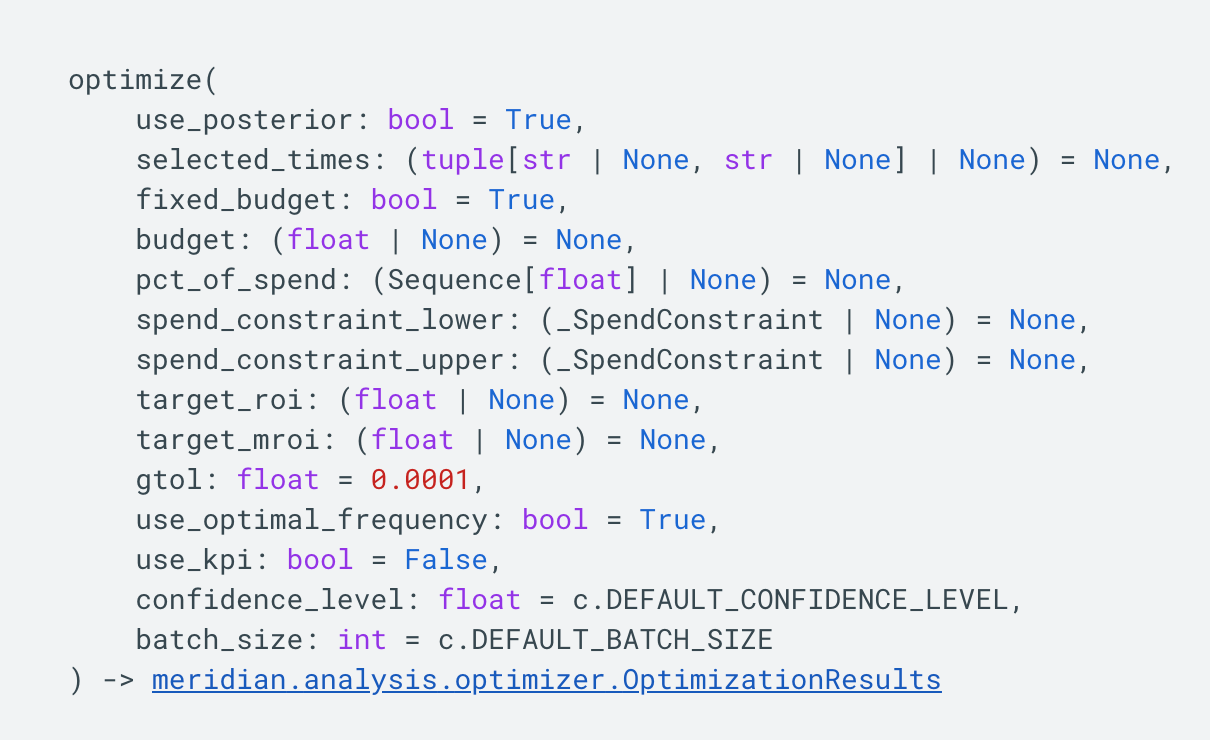
This allows you to modify the optimization scenario by selecting whether to run it with a fixed or flexible budget, choosing a target ROI or MROI for a flexible budget scenario, or defining a per-channel spend constraint.
The Budget Optimization Report consists of the following:
- Optimization scenario: Estimated Results for the Optimizer Scenario.

- Recommended Budget Allocation: Channel-level budget shifts and expected performance lift.
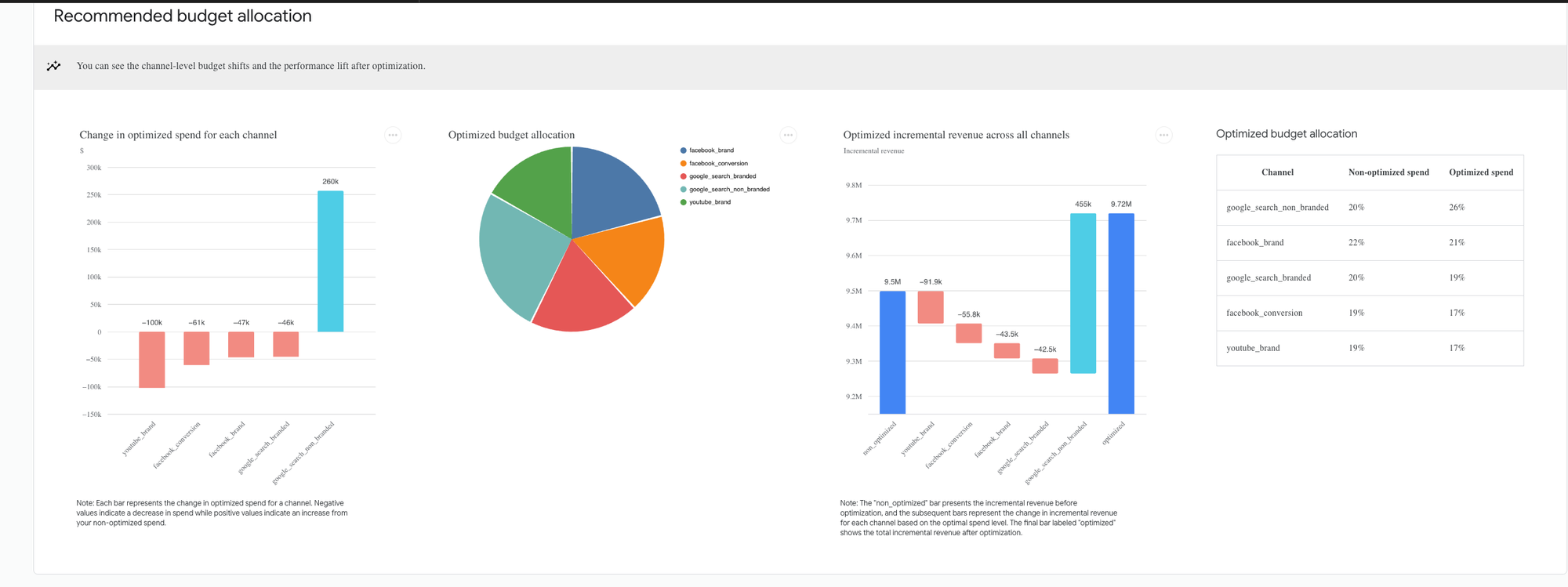
- Response Curves: Depicts the relationship between marketing spend and the resulting incremental revenue
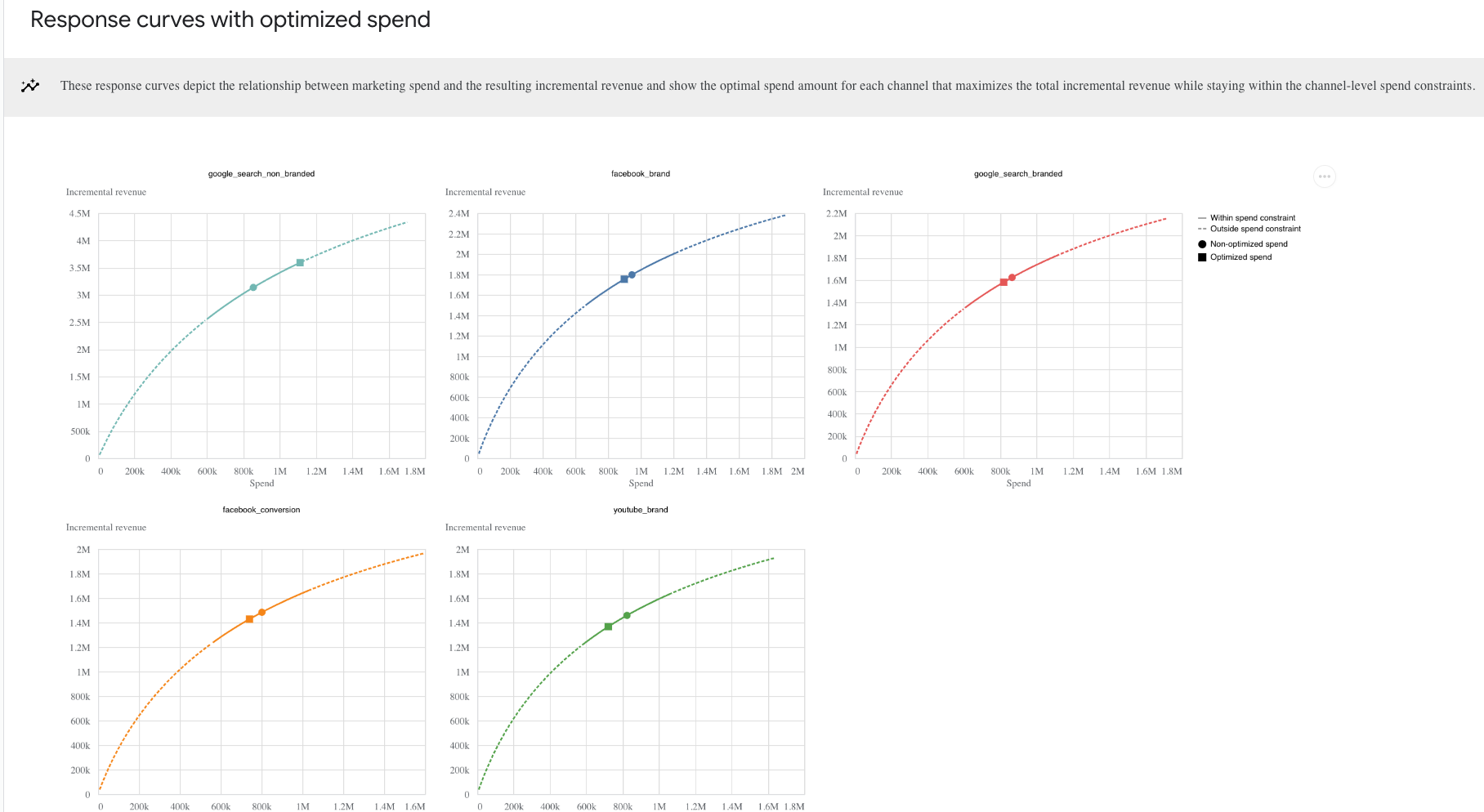
Evaluating Our Meridian Models Against Our Ground Truths
Okay, we've followed the process and now have two models to help us define our budget for next year. As a recap, we expected the model output to show the following ground truths:
- No Extremely Dominant Channel, But GADS Non-Branded is the slight winner: We used coefficients to model the data so that no overly dominant channel would be found. We should probably expect "Google Ads Non-Branded" to have a slightly higher ROI and effectiveness due to a higher upper bound in the random distribution.
- A High Baseline Revenue: Baseline revenue should be pretty high (Higher than 70% of revenue) due to the substantial impacts of seasonality and other confounding variables we hardcoded into the model.
Was GADS Non-Branded the Slight Winner?
I'd say both models performed well by estimating the impact of Google search non-branded as being generally higher than the other channels. However, while in the model with priors set, GADS Non-Branded was the clear winner, in the one without priors, the difference was marginal (only about a 10% higher ROI than the lowest impact channels.
The model with set Priors:
The model without set priors:
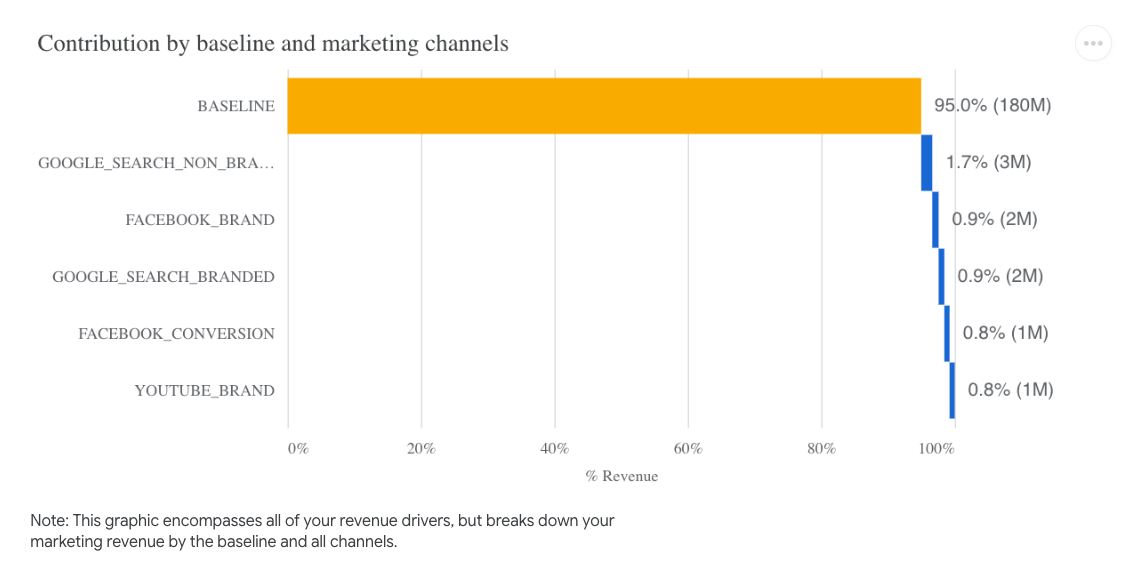
What about the baseline revenue?
Both models estimated a highly significant baseline revenue. While I expected the impact to be higher than 70%, the baseline revenue predicted by the model was around 95% of total revenue. Is this realistic? I'm unsure; I should probably look into changing my data generation process to have more "realistic" figures.
Parting Thoughts
Overall, I'm pretty happy with the results of this deep dive into Meridian. The model gave results that were close to what I expected when building the synthetic data.
As with all ML projects, the idea here would be to keep playing around with our model, feeding it more control variables and cleaner data, and defining a set of priors through experimentation to calibrate the model to those "ground truths."
From my hands-on experience, I can tell you that the documentation can be daunting, but with some experimentation and careful reading, you can have your MMM running in no time. I hope you feel more comfortable with MMM after reading this.